按【Ctrl+D】或拖动【 小墨鹰LOGO】到书签栏,收藏本站!
浏览量:5117 发布时间:2020-08-17 17:55:03
在微信AI背后,技术究竟如何让一切发生?关注微信AI公众号,我们将为你一一道来。今天我们将放送微信AI技术专题系列“微信扫一扫的技术与艺术”的第三篇——《微信扫一扫识物——离线系统篇》。
导语
什么是识物
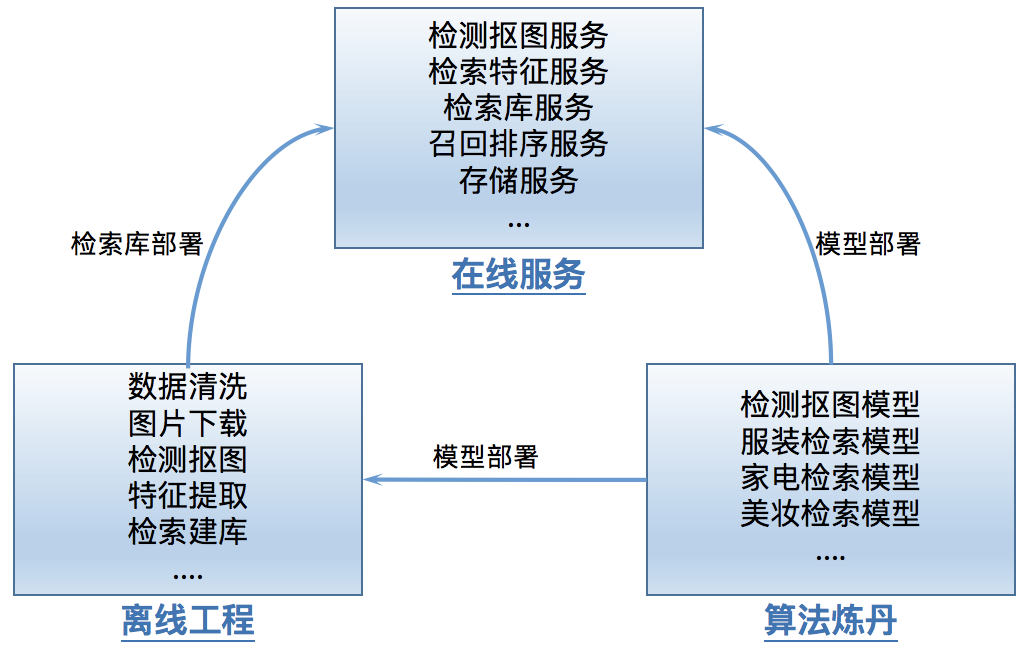
1. 算法模型
2. 离线工程
3.在线部署
挑战
1. 数据版本
2. 数据处理性能
3. 繁杂的流程
4. 数据质量
数据版本

2.1 检索库

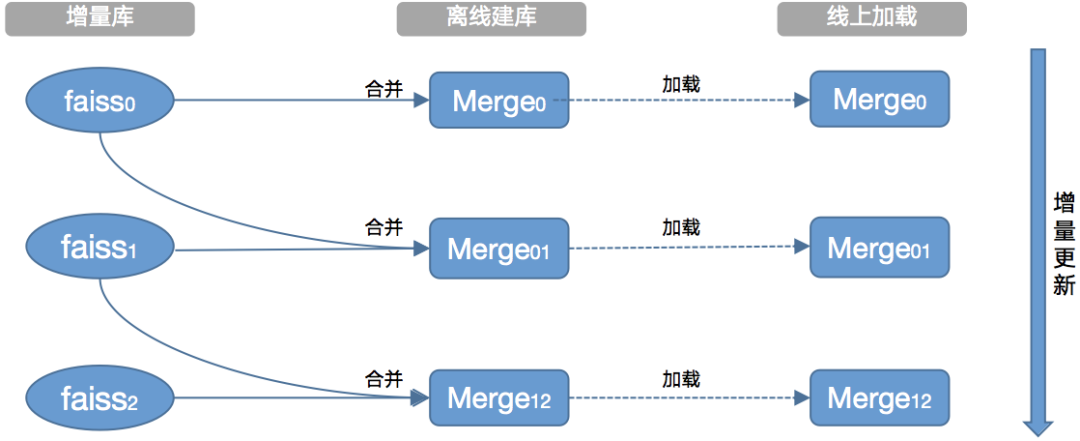
2.2 数据版本兼容
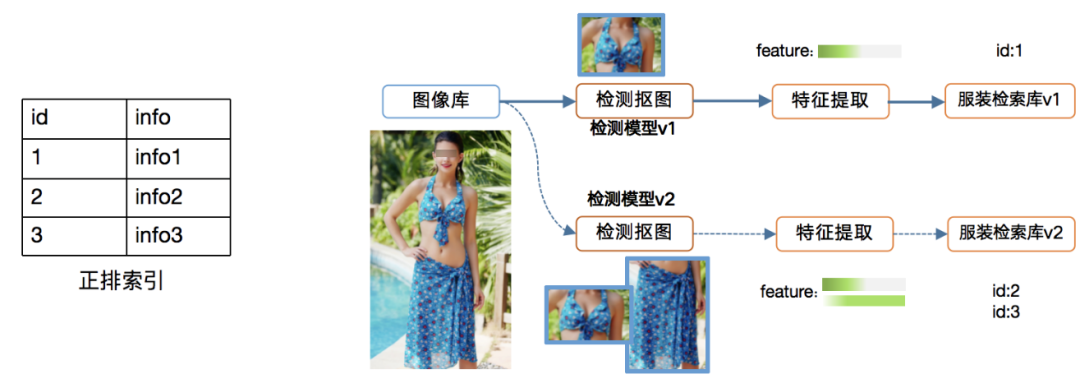
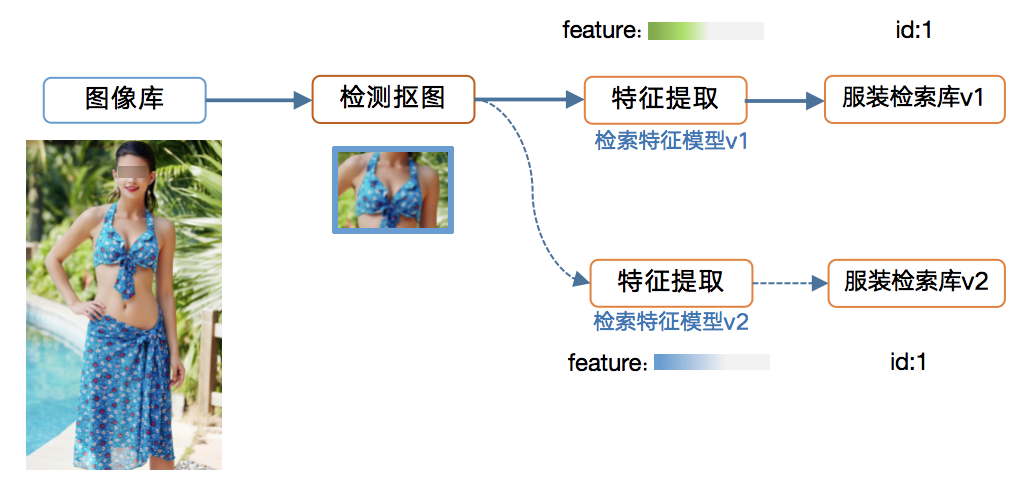
2.3 数据版本管理系统
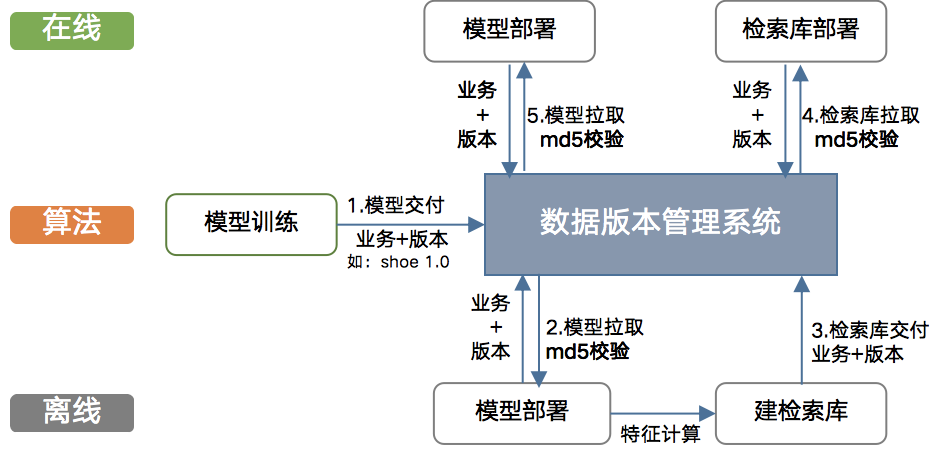
2.4 docker化
分布式计算
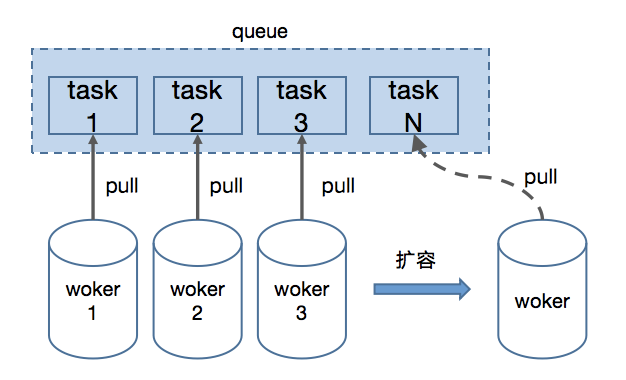
3.1 数据拆分
3.2 数据并行计算
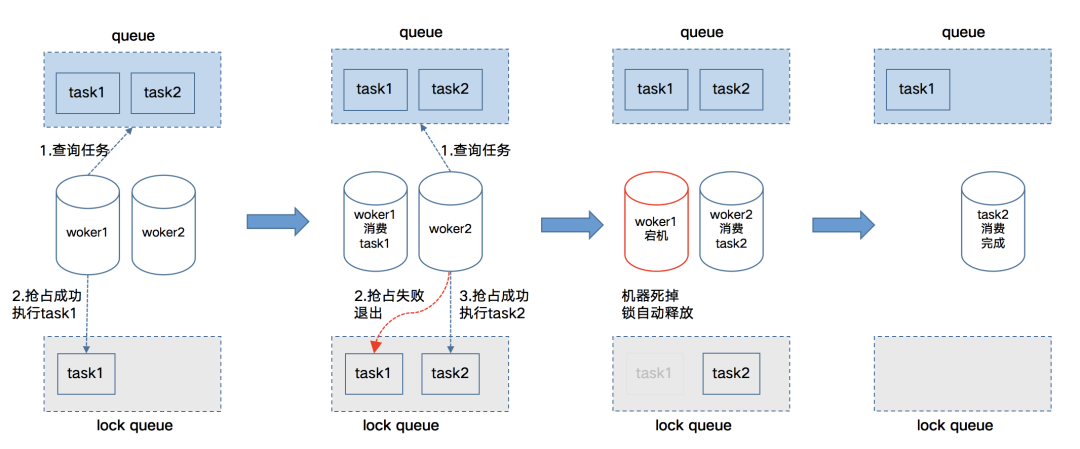
任务调度
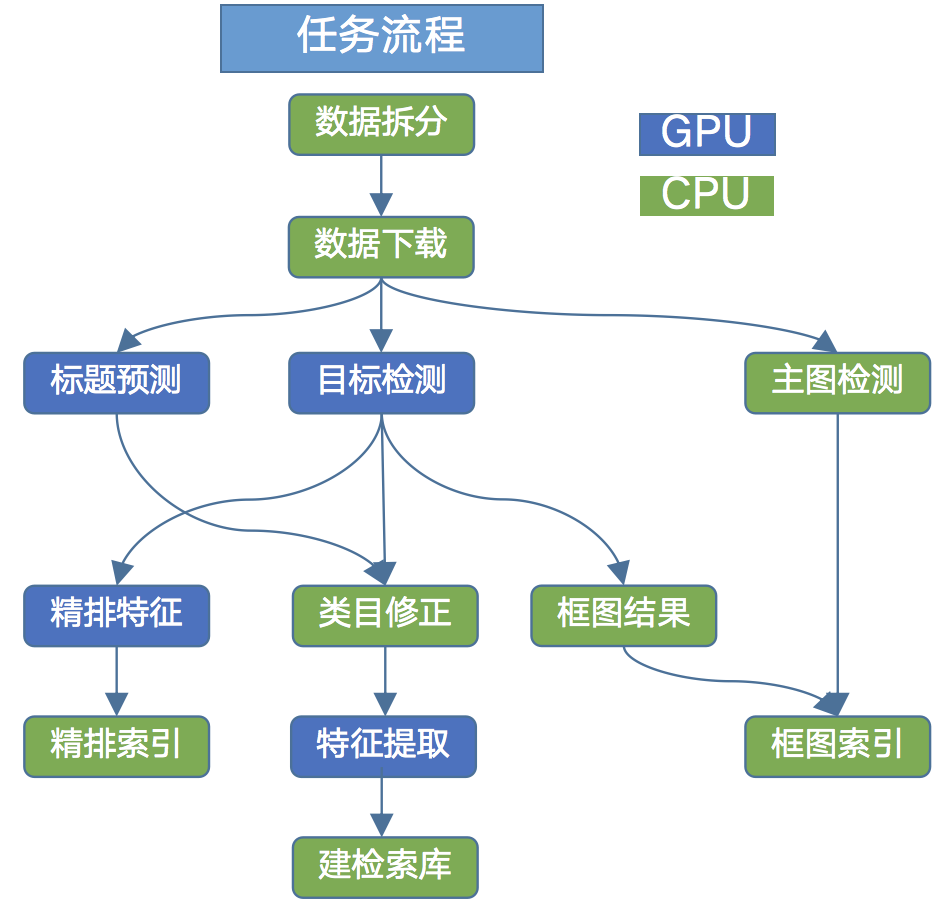
4.1 任务系统
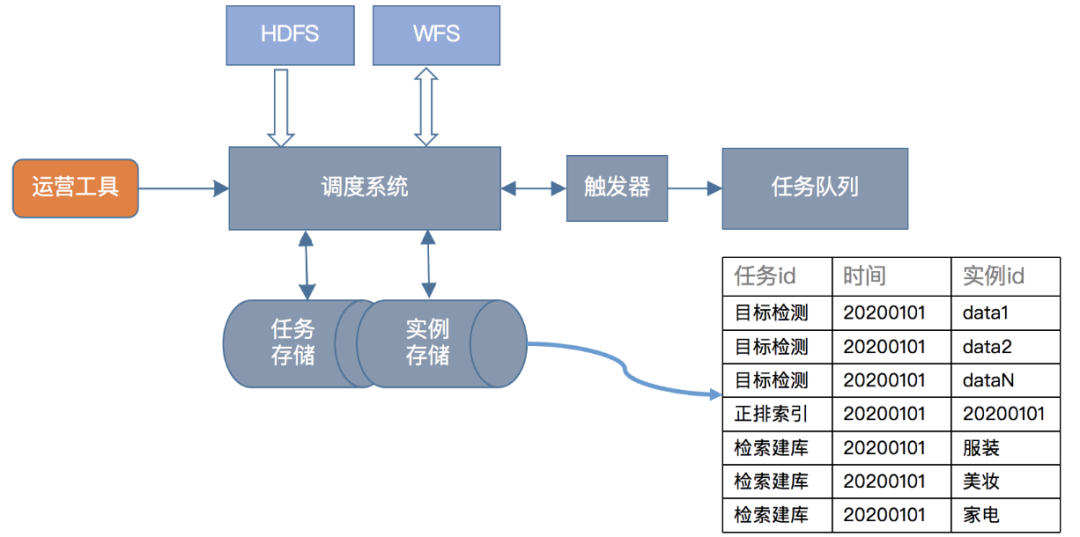
· 文件系统:文件系统这里使用了微信自研分布式文件存储系统的WFS,我们所有中间数据和结果数据都存放在这里
· 存储系统:主要有任务存储和实例存储,与一般实例存储不同的是,为了分布式计算,我们在数据维度和类目维度做了拆分,一个实例包含一个或多个子实例
· 调度系统:主要负责收集、管理任务状态,检查任务依赖
· 触发器:定时轮训调度系统,找到满足执行条件的任务实例
· 任务队列:存储待执行的任务实例,由worker获取依次消费
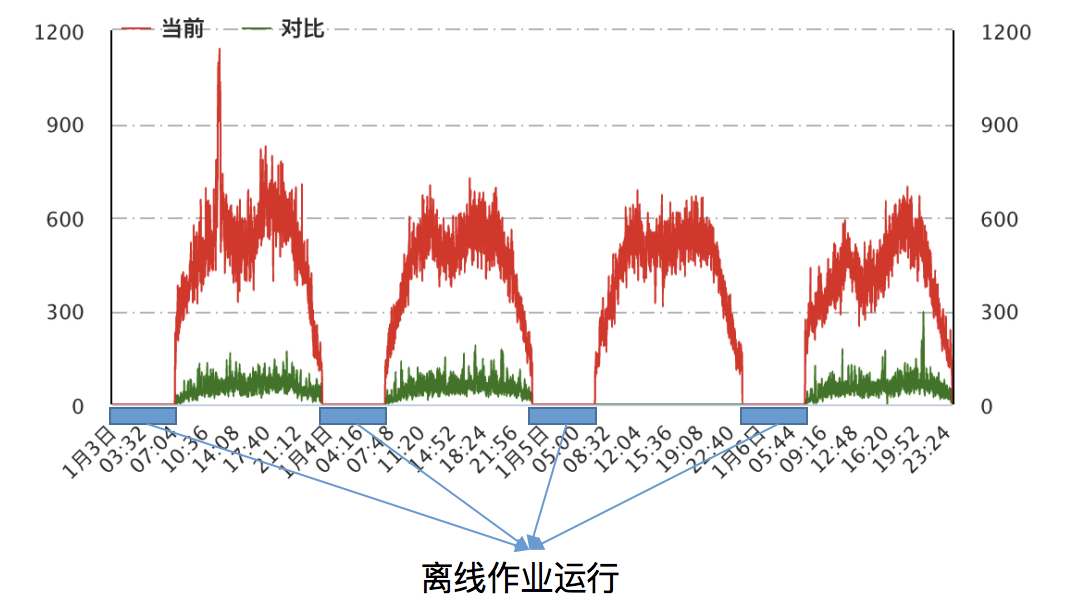
4.2 在线服务合并部署
数据质量
5.1 数据可视化

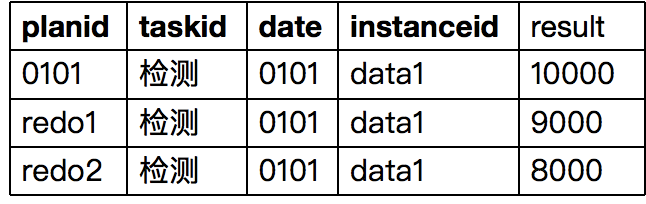
5.2 一致性检查
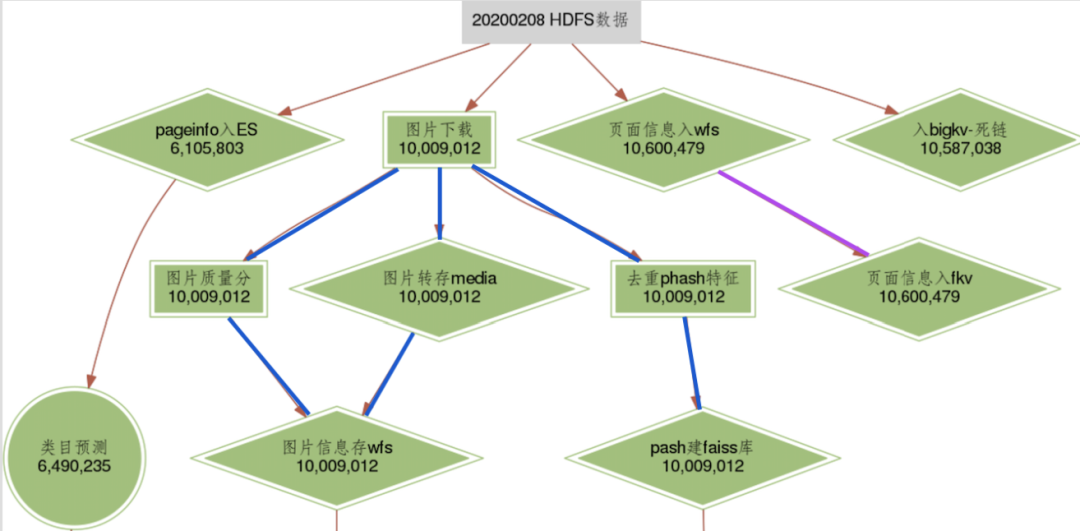
5.3 评测系统

5.4 数据淘汰

总结

微信在线客服
请提供详细的截图大图+文字说明您的问题



微信扫码查看帮助
扫码关注,获取各种排版小技巧,黑科技!复制成功
Copyright © xmyeditor.com 2015-2025 河南九鲸网络科技有限公司
ICP备案号:豫ICP备16024496号-1 豫公网安备:41100202000215 经营许可证编号:豫B2-20200040


