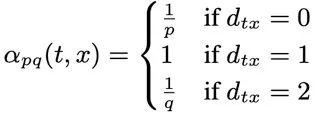Angel是由腾讯自研并开源的高性能分布式机器学习平台,它提供了用于特征工程,模型构建,参数调优,模型服务和AutoML的全栈设施。Angel-Graph作为Angel的通用型图计算引擎,已于今年五月份开源,能够轻松支持十亿级顶点、千亿级边的大规模图计算,并且提供了大量开箱即用的图算法,包括传统图挖掘、表示学习和神经网络相关算法,为支付、推荐、游戏、风控、图谱等多个业务场景提供计算服务。近期,Angel-Graph再次对大家常用的六款表示学习和神经网络学习算法,在算法精细度、可选参数、工程性能等方面进行了升级和优化。
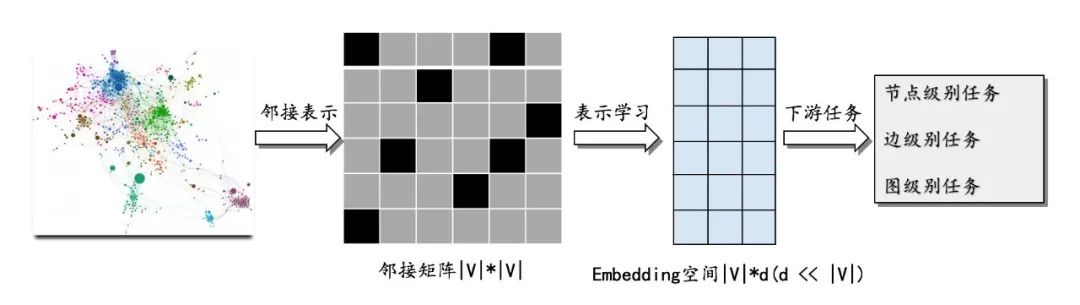
引言 图表示学习 在机器学习任务中得到广泛应用,其主要目标是将高维稀疏的图数据转化成低维稠密的向量表示,同时尽可能确保图数据的某些特性在向量空间中得到保留。而学习得到的低维向量则可以进入各种下游任务,比如分类、聚类、链路预测以及可视化等。图1展示了图表示学习的整体过程:
图表示学习方法大体可分为三类:基于分解的方法、基于随机游走的方法以及图神经网络方法。 其中基于分解的方法通过对描述图数据结构信息的矩阵进行矩阵分解,将节点转化到低维向量空间中去,同时保留结构上的相似性。缺点是时间和空间复杂度高,难以处理大规模的图数据。 基于随机游走的方法将在图中随机游走产生的序列看作类似NLP问题中的句子,节点看作词,以此类比词向量从而学习出节点的表示,典型的方法比如DeepWalk[1]、Node2vec[2]、MetaPath2vec[3]等。最大的优点是通过将图转化为序列的方式从而实现了大规模图的表示学习。 图神经网络凭借其强大的端到端学习能力,能够自动融合拓扑和节点属性特征进行学习,越来越受到学术界和工业界广泛的关注。本文主要阐述了基于Angel-Graph图计算框架实现的基于游走和图神经网络的表示学习方法及其工程优化实践。 Angel-Graph图计算引擎
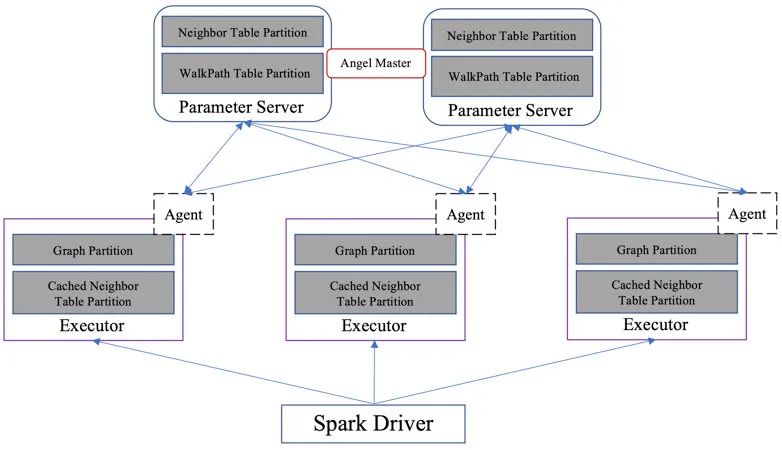
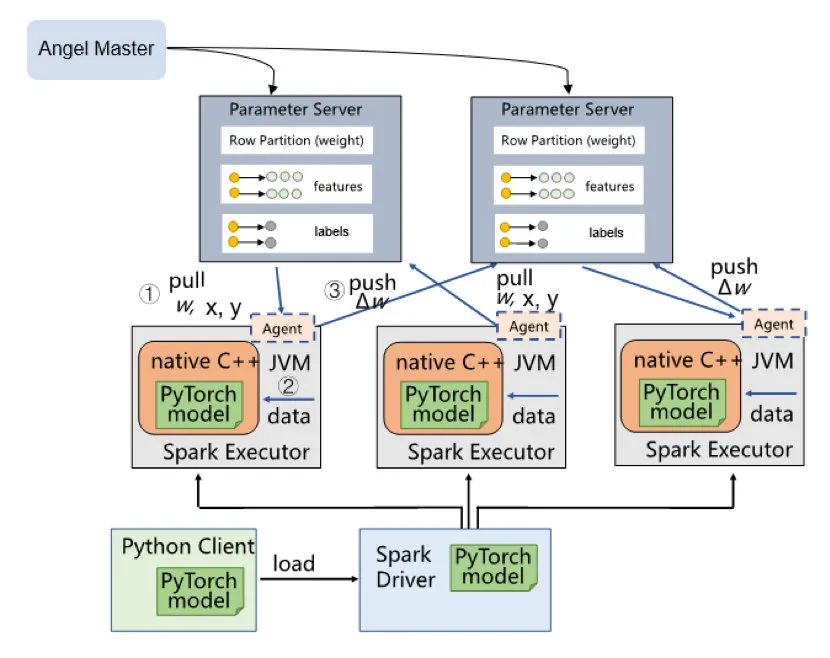
基于Angel-Graph图计算框架的实现的图表示学习架构设计如图2所示,参数服务端(Parameter Server)存储了节点的邻接表以及每个节点的游走路径信息,Spark Executor端存储了边的分区数据以及对邻居节点的cache数据,Angel Agent则作为代理桥接Spark Executor和Parameter Server。该架构设计有如下优点: 高扩展性:Angel的参数服务器可以水平扩展,存储十亿甚至百亿规模的参数;Spark则可以处理TB级别的数据。同时二者均可以运行于大集群之中,不会受到资源申请的限制。 端到端处理:Spark提供了ETL数据处理能力,读写TDW/HDFS的能力 支持稀疏数据:Angel的参数服务器为高维稀疏模型而设计,可以支持图节点的稀疏编码 高容错:Spark自带了容错能力,Angel的参数服务器也具备状态恢复能力 1. Graph Embedding算法 1.1 DeepWalk 1.1.1 原理 2013年Word2Vec的出现对工业界和学术界产生了极大的影响,通过句子序列刻画词与词的邻居共现关系,Word2Vec进而学习到词的向量表示。KDD2014的DeepWalk算法也借鉴了Word2Vec的思想,通过使用随机游走(RandomWalk)的方式在图中进行节点随机采样,最终形成一条条贯穿网络的路径,进而捕捉节点间的共现关系。RandomWalk是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件,下图所示绿色部分即为一条随机游走示例:
图中以根节点 DeepWalk算法的伪代码如下,主要包括两个步骤,第一步为使用随机游走策略进行节点采样,生成节点序列;第二步为使用skip-gram模型word2vec学习表示向量,将节点映射到低维空间。
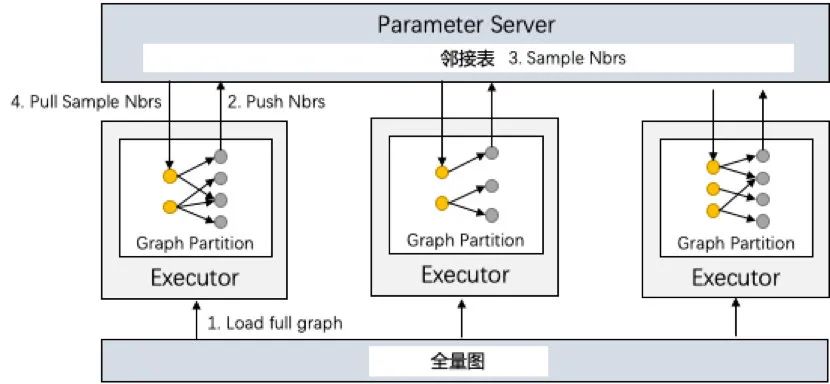
1.1.2 实现方案以及工程优化 我们使用Angel-Graph图计算框架分别实现了DeepWalk算法中的随机采样部分和基于skip-gram方法的Word2Vec部分,在实际使用只需要将两个步骤串行使用即可得到最终的结果。本节主要描述随机游走部分的实现,从存储架构上来讲,Spark Executor存储图的边的分区以及每个节点对应的采样路径,Angel参数服务器上则会存储节点邻接表。具体计算流程如下图所示:
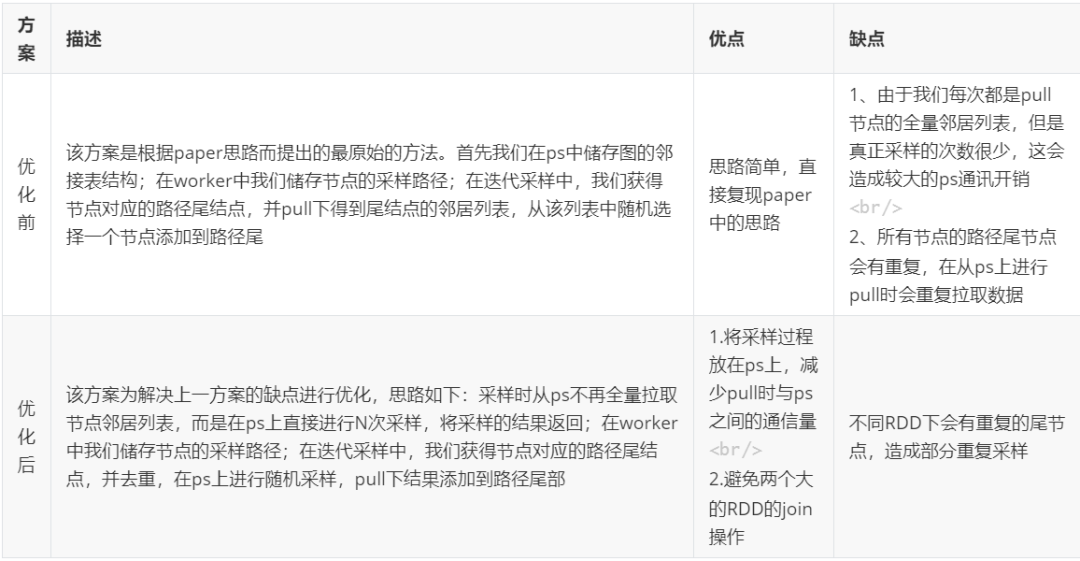
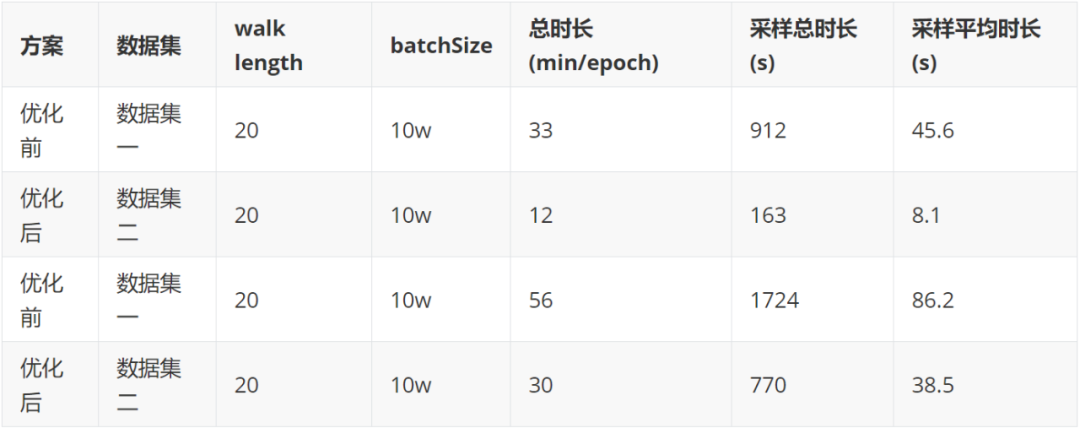
1)初始化:将节点的邻接表push到Angel参数服务器存储,该表后续不再进行更新;Executor中将节点采样路径初始化为该节点自身 2)随机采样:每一轮迭代时,获取每个节点采样路径尾节点,并在Angel参数服务器上对尾节点的邻居进行随机采样 3)路径更新:将第二步中得到的采样节点pull下来添加到Executor对应节点路径尾部 在实现的过程中,我们将邻居采样过程放在参数服务器上进行,这样就避免了在Executor中将节点整个邻居全部拉下来,减少与参数服务器的通信开销;而在Executor中,每个partition下所有节点的路径尾节点可能会存在重复节点,我们不需要从参数服务器重复性地采样,而是将partition中尾节点进行计数统计,并从参数服务器一次性采样对应个数的邻居节点,避免与参数服务器冗余通信。 1.1.3 性能以及效果测试 我们使用7.5亿顶点,60亿边的数据集进行测试,对所有节点完成一轮路径采样耗时约为40min分钟,单独一次采样时间为1min左右。此外我们拿优化前和优化后的方案在不同的数据集下做了性能测试,详细可参考下述表格。
(点击查看大图)
两个方案方案性能对比,我们使用两个无权重数据集进行性能测试,数据情况如下:
运行时间对比如下表所示,我们可以看到优化后的版本在总体运行时间尤其是采样时间都有很大程度减少:
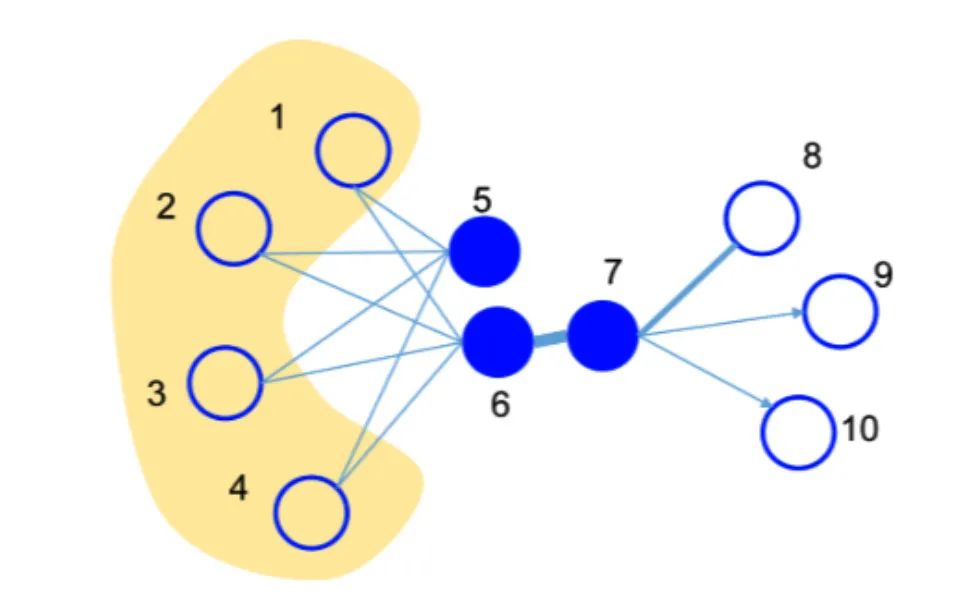
1.2 Node2vec 1.2.1 原理 图数据中节点间主要存在两种相似关系,homophily equivalence(同质性)与structural equivalence(同构性)。其中,具有homophily equivalence关系的节点在图结构中表现为构成紧密相连的领域,如图6中的{
不同的随机游走策略能够挖掘图中节点不同的相似信息。上文中提到的DeepWalk算法是基于uniform的采样策略提出的图表示学习算法,所谓uniform的游走策略是当walker处于任意节点时,其以“等概率”采样方式到达邻居节点中的一个,该策略本质上属于DFS(深度优先搜索),其主要提取图中节点的homophily equivalence相似关系,而难以充分提取structural equivalence相似关系。LINE算法有所不同,其基于BFS(广度优先搜索),主要提取structural equivalence相似关系而弱化了homophily equivalence相似关系。Node2Vec算法的随机游走策略吸取了二者优势,灵活结合了DFS与BFS,能够同时提取图中节点的homophily equivalence与structural equivalence两种相似关系,被称为dynamic游走策略。接下来我们简述这种策略。
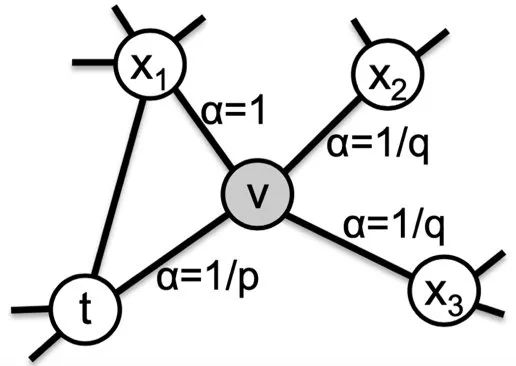
如图7所示,假设walker目前处于节点V并采用uniform游走方式,那么下一步walker到达π
另外,{ 1.2.2 实现方案以及工程优化 Node2Vec随机游走采样算法在Angel-Graph框架具体的计算流程如下: 邻接表和walkpath初始化:在每个边RDD分区中,executors并行地收集该分区中的节点-邻居集数据,然后push到参数服务器中的邻接表分区;基于初始化好的邻居表分区,将路径的前两个元素初始化为该节点的ID以及其随机采样的邻居节点ID完成节点-随机游走路径表的初始化。
游走节点采样计算与walkPath更新:游走节点采样计算与walkPath更新是在各个partition并行进行的,在每个partition中进行采样操作直到次数达到所设定的walkLength停止条件后结束。其具体的操作为:
1)第一步为在每个executor数据分区内根据设置的batchSize拉取参数服务器上对应分区节点walkpath的最后两个节点ID(所拉取的两个节点ID分别为dynamic采样的当前节点和前一节点)。由于后续采样计算需要这两个节点的邻居集信息,因此,各个executor将对应的节点-邻居集数据拉取至本地;
2)第二步则是本地进行采样计算,在计算获得新的采样节点后,executor将采样结果push到参数服务器上的walkPath的对应部分进行更新,在dynamic随机游走实现中,相比于PartialSum与AliasTable方法,rejection sampling(拒绝采样)是较为高效的采样方式,其无需对转移概率进行预处理,实现每个节点每次采样的时间复杂度和空间复杂度分别为O(k)与O(1),其中k为平均尝试次数,在较理想的情况下,k是一个接近于1的数。因此,我们采用了rejection sampling方法,关于rejection sampling方法细节可参考论文[4]。
结果保存:当整个游走完成后拉取参数服务器上所有的walkpath保存为最终游走结果
由于不同次操作可能拉取相同节点的邻居集数据,为了尽量避免重复拉取增加耗时,我们在各个excutor上分出一块存储空间用于存储已拉取的节点-邻居集数据(以参数cacheRatio作为控制cache存储空间占excutor总空间的比例),之后若需要相同节点的邻居集信息便可以直接从本地读取,减少和参数服务器的通信耗时;此外有些图数据可能非常稠密,可能存在多个超级顶点,超级顶点的度可能达到几百万级别,这会导致拉取这些节点的邻居集的时候超时甚至不能拉下来,针对这个问题,我们会对这些超级节点的邻居集在参数服务器上分段存储,拉取的时候也同样分片拉取解决。 1.2.3 性能以及效果测试 我们在6.5千万点、18亿边以及7亿点、60亿边的业务数据集上对所实现的Node2Vec算法分别进行了测试,详细测试结果如下表所示: 表 4. Node2Vec算法流程各主要环节耗时性能结果
(点击查看大图)
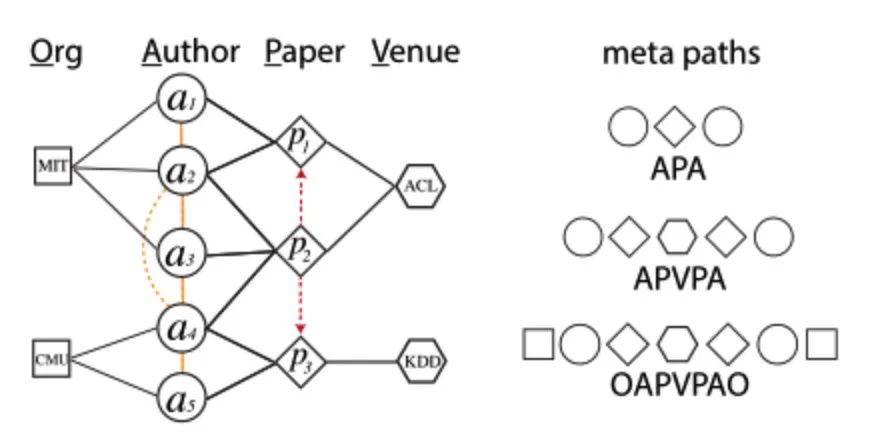
1.3 MetaPath2vec 1.3.1 原理 MetaPath2Vec是一种从异构图上得到有效游走路径,并利用异构skip-gram(负采样时只采样当前类别的节点)方法的Word2vec模型训练得到图中各节点的embedding向量的方法。那什么是异构图呢,简单来说异构图是一种由多种不同属性的节点及其之间的连边构成的网络,即点的类别个数 + 边的类别个数 > 2,如下图异构网络所示,图中有Org、Author、Paper、Venue四种不同类型的节点。与DeepWalk不同的是,为了保留网络中节点的属性信息,MetaPath2Vec通过定义合适的metaPath路径来控制随机游走的方向。metaPath路径是由不同的顶点属性构成的对称序列,规定了当前节点的下一个采样范围。比如对于下图中的“APVPA”,当当前节点的属性是A(Author)时,下一个采样节点必须是属性为P(Paper)的节点,采样概率则与边的权重相关。
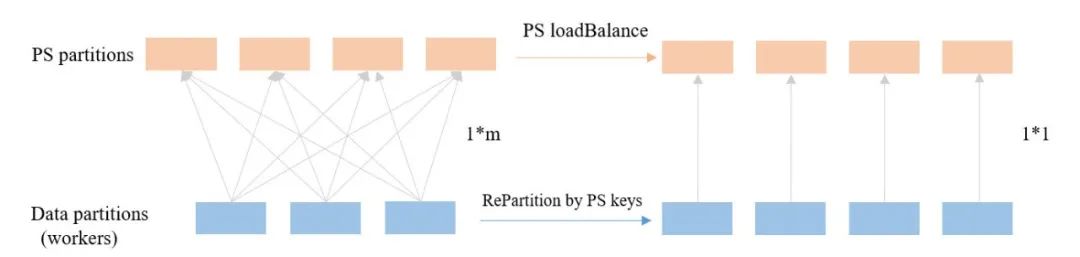
1.3.2 实现方案以及工程优化 对于无权图的采样,可以随机从采样范围中选择一个节点,此时采样的时间复杂度为O(1);对于带权图,需要按照每个节点的边权重分布进行采样,此时时间复杂度为O(n)。为了提升采样效率,我们采用AliasTable方法,用空间换时间,将复杂度降低至O(1)。AliasTable是一种将离散非均匀分布转换成离散均匀分布后进行采样的方法,广泛应用在各种图游走中,具体可参考论文[5] MetaPath2vec的游走部分在Angel-Graph图计算框架的分布式实现逻辑如下: 1)每个节点按照给定的metaPath生成自己的AliasTable,将所有节点的aliasTable推到参数服务器上去(由参数服务器完成两步采样步骤,回传采样结果给executor端); 2)以所有节点为游走初始点同时开始采样,统计该批次各采样顶点需要采样的次数,一次性从参数服务器获得该采样点的采样结果,分配到每条路径中去; 为了提升游走效率,我们设计让ps和worker的各分区进行1对1通信来减少二者的通信连接数。具体做法是在每批次采样前,将参数服务器的数据分区同步映射到Spark的数据分区,保证参数服务器和executor间的分区一致性。这样做的好处是可以大大减少executor和参数服务器的通信连接,减少了数据分发和结果合并的耗时。该方法同时存在一个问题,即数据分区数与ps分区数一致,当数据量比较大时,任务并行度会受到限制。解决方法是将参数服务器分区进行拆解映射,此时参数服务器分区数和executor数据分区数不是1对1,而是1对n(n值较小)。此外,随着游走路径的加深,各采样点的采样压力会因边权重(对于无权图则是入度)的倾斜而不均衡,可以通过对ps端进行均衡分区来解决。具体来说,对于入度较大的节点所在的ps分区,节点数会相对少一些,来缓解该分区被频繁访问的压力。通过以上方式,可以使整体的采样效率有3倍的提升 。
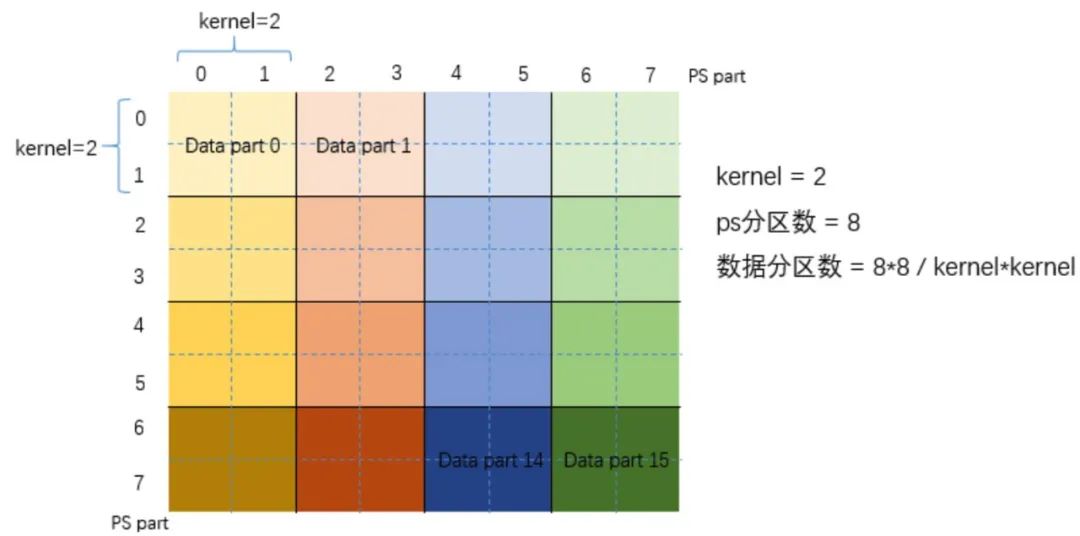
当数据规模较大时,ps的分区个数会限制worker的计算并行度(通常ps分区个数不会设很大,而数据分区个数需要与ps保持一致)。在这种情况下,我们提出了SquarePartitoner的分区方式,如下图所示。当ps分区个数为8时,数据分区为8*8=64,其中第0个数据分区中的src和dst节点都位于ps的第0个分区,而第1个数据分区的src和dst节点分别位于ps的第0和第1个分区,以此类推。当ps分区个数较大时,会出现数据分区爆炸的问题(如ps分区数为400,则数据分区数为16000),这时引入kernel的概念来缩小数据分区规模。比如kenel=2时,相邻的4个分区被合并为一个,可以保证数据分区不爆炸的情况下,单个数据分区需要通信的ps分区的数量也不会很多。
1.3.3 性能以及效果测试 我们在7亿点,30亿边规模的业务数据上对算法性能做了测试。首先为了测试SquarePartitioner的有效性,我们在两个通信时间消耗较大的算法word2vec和line上与hashPartitioner进行了性能对比,可以发现SquarePartitioner在两个算法上每轮迭代的时间都约为HashPartitioner的三分之一。
图 11. SquarePartitioner在word2vec和line上的性能提升 而在MetaPath的游走部分,当游走长度为30时,优化后总的游走耗时约28min,平均每轮约<1min,相比优化前性能提升了3倍 1.4 LINE 1.4.1 原理 同DeepWalk一样,LINE(Large-scale Information Network Embedding)也是一种基于邻域相似假设的方法,只不过与DeepWalk使用DFS构造邻域不同的是,LINE可以看作是一种使用BFS构造邻域的算法。此外,LINE还可以应用在带权图中(DeepWalk仅能用于无权图)。
LINE定义了两种节点相似度:一阶相似度和二阶相似度。一阶相似度为直接相连的节点之间的相似,形式化描述为若 LINE算法的实现就是基于这两种相似度分别优化两个目标函数: 其中,P1刻画了节点之间的一阶相似性(直接连边),P2刻画了节点之间的二阶相似性(相似邻居)。换句话说, 如果两个节点之间有连边,那么在嵌入的向量空间中两个节点也要靠近 如果两个节点的邻居是相似的,那么在嵌入的向量空间中,两个节点也要靠近 1.4.2 实现方案以及工程优化 LINE最初的实现方案是将节点的embedding向量按维度拆分到多个参数服务器上,节点之间的点积运算可以在每个参数服务器内部进行局部运算,之后再拉取到spark executor端合并。executor端计算每个节点的梯度,推送到每个参数服务器去更新每个节点对应的向量维度。它的优势在于避免了传输模型导致的大量网络IO,适用于节点编码向量维度较高的场景。但是此方案的缺点就是节点编码维度必须是模型分区个数的整数倍,这限制了模型分区的个数和计算并发度,此外,在实际的使用过程中训练的embedding向量的长度一般都不会超过300,那么使用此种方案效率并不高,因此,新的实现方案我们不在将节点的embedding向量进行切割,而是一个整体存在参数服务器,此外,我们使用节点id范围划分模型,没有分区个数限制,提高了计算的并发度,完整的实现架构流程可参考图5,其在参数服务器端存储的不再是邻接表,而是节点及其embedding向量。 1)数据存储:Spark Executor端存储边表,节点则按range partitioner的方式分布式存储在参数服务器端,每个节点有两个embedding向量,分别表示自身节点的embedding向量以及产生上下文顶点的embedding向量,embedding向量不做切割。从宏观视角来看参数服务存储的就是两个 2)计算:参数服务器节点向量做初始化,executor端在每个数据分区内按batch去拉取节点、上下文节点以及负采样节点的的embedding向量做点积运算,然后计算梯度。由于需要拉取大量的节点embedding向量回executor本地进行计算,因此会产生大量的网络通信开销,因此我们会对拉取的参数在传输的时候做精度压缩,将单精度浮点数压缩成半精度浮点数传输,能够减少一倍的通信量。此外数据的分区策略我们仍然采用metapath实现里提到的优化分区策略,并且在每个batch内采用局部负采样的方法来获取负样本数据,该优化策略能够大大减少embedding向量拉取以及梯度push到参数服务器的耗时。上述精度压缩、分区策略以及局部负采样优化使得性能较之前能提升60%。 3)更新:将上一步计算得到的每个节点的梯度push到参数服务器做更新,同样使用压缩传输。 由于跑LINE算法一般数据量级都很大,因此我们做了很多容错措施,比如定期写checkpoint,节点挂掉模型恢复等操作,此外我们还提供增量训练的功能。 1.4.3 性能及效果测试 我们在节点数8亿,边数125亿的业务数据上分别对带权和不带权版本的LINE算法做了性能测试,边不带权的有向图,每个节点Embedding的维度为128 ,每个epoch耗时 37.5分钟;边带权的有向图,每个节点Embedding的维度为128,模型初始化+全局alias table构建时间20分钟,每个epoch耗时 41分钟,详细如下表所示。
(点击查看大图)
2. GNN(Graph Neural Network)算法 2.1 GAT 2.1.1原理 GAT(Graph Attention Network)[7]网络是一种基于空间的图卷积网络,它的注意机制是在聚合特征信息时,将注意机制用于确定节点邻域的权重。GAT网络使用masked self-attention层解决了之前基于图卷积(或其近似)的模型所存在的等权聚合问题。其基本思想是,根据每个节点在其邻节点上的attention,来对节点表示进行更新。在GAT中,图中的每个节点可以根据邻节点的特征,为其分配不同的权值。GAT的另一个优点在于,无需使用预先构建好的图。
为了计算每个邻居节点的权重,通过一个F'×F的共享权重矩阵W应用于每个节点,然后即可计算出attention系数: 为一个共享注意力机制,即 当得到attention系数后,便可以利用如下公式得到节点的embedding输出: 如上图右边所示为了能够更稳定的表示节点的embedding特征,还可以使用多头注意力机制,即同时使用 2.1.2 实现方案以及工程优化 从算法的描述中可以总结出该算法的大体可分为:计算attention系数和计算embedding;其中计算attention系数时需要节点、该节点所有邻居,及这些节点的特征,计算embedding的过程则是对节点特征卷积的加权平均。该过程与GraphSAGE类似,但不同的是GraphSAGE会对邻居进行采样并且会有不同阶数采样,而GAT目前只使用一阶邻居。因此我们可以使用PyTorch on Angel中的GCN框架来实现,并针对GAT的特点进行邻居特征聚合。GAT实现框架如下图所示:
1)数据存储:节点的属性及算法参数存储在参数服务器上,边的信息存储在executor上。 2)数据准备:选取批量点作为中心,通过executor上的边信息获得这些点全部的一阶邻居节点,并从参数服务器上拉取节点对应的属性特征 3)聚合计算:利用在python端定义网络结构进行前向计算,并借助PyTorch的自动求导功能计算出梯度。其中注意力系数与embedding的前向计算公式如原理篇所示。 4)梯度更新:网络中算法参数大小数量由用户定义的图网络决定并初始化,通过加载模型文件将权重传到参数服务器端,以row partition格式存储,计算时从参数服务器端拉取,通过后向计算更新后将梯度再更新到参数服务器上。 从原理中可以知道,GAT算法属于基于空域的GNN,因此在计算中不需要获得全图的信息,这样可以使得在计算中能够进行小批量并行计算,从而提升算法整体性能。此外图神经网络的节点特征一般都是只读的,因此我们在节点特征初始化后就将序列化好的特征存储在参数服务器上,这样就可以减少每次去拉取节点特征时序列化写的时间。 2.1.3 性能以及效果测试 为了验证算法的性能,我们在内部业务数据上进行了验证,在6亿点,8亿边的数据规模,计算迭代一轮耗时50s左右(其中包含计算训练结果指标与验证结果指标,如acc); 此外我们在公开数据集Cora上进行效果验证,与论文实验结果相比,准确率有1个点的提升。
(点击查看大图)
2.2 二部图GraphSage 2.2.1 Bipartite GraphSAGE原理 二部图上的表示学习任务在很多实际场景中有重要的应用价值,例如推荐系统,电商交易等。在这些场景抽象的图模型中,图中节点往往对应着两种不同角色(例如推荐系统中的user-item节点), 天然地对应着二部图的结构。传统的图表示学习算法,例如GraphSAGE, Random Walk等研究对象多在同构图上,而缺少了对异构图的建模能力。Bipartite GraphSAGE[8]算法则将同构图上的GraphSAGE扩展到二部图上,对二部图上的两种类型的节点都有很好的表征能力。一个二部图中存在两种节点,假设我们称之为user节点和item节点,图中的边只存在于user-item之间,而相同类型的节点之间无边相连。
二部图graphsage的主要思想是分别对user节点和item节点进行邻域信息聚合。在每一轮聚合中,一个user节点从它邻居item节点聚合信息,同样,一个item节点从它邻居user节点聚合信息。随着不断迭代进行聚合,图中每个user和item节点的embedding都包含了更大感受域的信息。
在第 同样地,对于item节点 其中 接下来,将聚合后的邻居信息与节点自身的embedding进行拼接,经过一个非线性激活层后,得到的结果即为此轮迭代后的节点embedding。 其中, 学习过程采用非监督的方式,在不依赖实际任务的情况下,根据图结构的显式或隐式信息,对模型参数进行更新。对于图中有边相连的节点,它们的embedding应该更加相近,而对于无边相连的节点,它们的embedding应该不相近。二部图对应的损失函数形式如下: 其中, 2.2.2 实现方案以及工程优化 在Angel-Graph图计算框架实现二部图GraphSage需要解决三个问题: 如何加速迭代过程
1)数据存储:从存储架构上来看,Spark Executor存储每个子图分区,Angel参数服务器上存储则需存储userGraph (user节点的features,user节点的邻接表),itemGraph(item节点的features,item节点的邻接表)。这些信息在参数服务器上存储,有利于后续的采样操作。同时,将user节点的信息与item节点的信息分开存储,有利于索引ID的简化,即user与item属于独立的ID体系,用户的输入数据中,无需对节点ID进行额外的预处理来区分两类节点。
2)邻居采样方式:节点一阶邻居采样我们放在executor端来做,直接根据每个graph parition中存储的邻接表即可,快速高效;而二阶及更高阶邻居采样则依赖参数服务器,将采到的一阶邻居push到参数服务器上,使用psf进行二阶或更高阶邻居采样。
3)minibatch迭代方式:在算法原理部分,我们介绍了每轮迭代需要对所有的节点根据聚合信息进行embedding更新。在我们的实现中,为了加速迭代过程,采用了小批量(minibatch)的迭代计算。实现方式与GraphSAGE的小批量迭代过程相似,即在每个minibatch中,我们需要在采样阶段就获取到该批次节点的P阶邻居。根据每个minibatch中的节点,先获取这些节点的一阶邻居,再获取到一阶邻居的邻居,以此类推。将所有这些邻域节点的features以及采样到的边均一次性输入神经网络的前向迭代流程中,完成一个minibatch的更新。二部图中,采样方式的区别在于,对于user节点,采样路径按照user-item-user-item..的metapath进行,而对于item节点,则按照item-user-item-user…的方式进行。通常采样到二阶就能达到较好的效果,至于采样邻居个数,假设采样一阶
4)小批量更新:在每个minibatch中,节点embedding的更新方式与全量节点的更新方式类似。以聚合2阶为例,假设该minibatch节点集合表示为
第一步:所有节点聚合各自的邻居(
第二步:节点
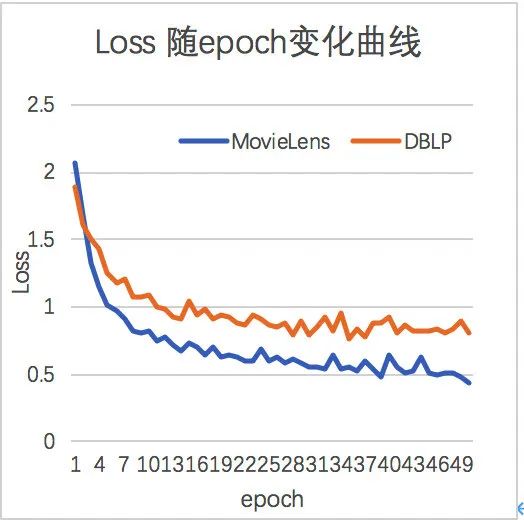
2.2.3 性能及效果测试 为了验证算法有效性,我们在两个公开数据集movielens和dblp上进行了实验,其收敛曲线如下图:
可以看到算法能较快的收敛,到第10个epoch已基本达到比较稳定的状态。 3. 总结 本文主要介绍了目前主流的图表示算法在Angel-Graph图计算框架上的分布式实现。目前上述算法均已开源到Angel项目,欢迎大家尝试使用,提出宝贵的意见和建议,帮助我们一起改进。此外,上述优化的算法我们也会部署到腾讯云 供大家使用,敬请期待。我们将继续对现有Angel-Graph图计算框架进行性能优化和功能补充。 4. 参考文献 [1]: DeepWalk: Online Learning of Social Representations. [2]: A. Grover and J. Leskovec, “node2vec: Scalable feature learning for networks,” in Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, 2016, pp. 855– 864. [3]: metapath2vec: Scalable Representation Learning for Heterogeneous Networks. [4]: K. Yang, M. Zhang, K. Chen, X. Ma, Y. Bai, and Y. Jiang, “Knightking: A fast distributed graph random walk engine,” in Proceedings of the 27th ACM Symposium on Operating Systems Principles, ser. SOSP 19. New York, NY, USA: Association for Computing Machinery, 2019, p. 524537. [Online]. [5]: Darts, Dice, and Coins: Sampling from a Discrete Distribution. [6]: LINE:Large-scale Information Network Embedding. [7]: Velikovi P , Cucurull G , Casanova A , et al. Graph Attention Networks[J]. 2017. [8]: Li et al ., "Hierarchical Bipartite Graph Neural Networks: Towards Large-Scale E-commerce Applications," 2020 IEEE 36th International Conference on Data Engineering (ICDE) , Dallas, TX, USA, 2020, pp. 1677-1688, doi: 10.1109/ICDE48307.2020.00149.
注:此文章来源于企业微信。