按【Ctrl+D】或拖动【 小墨鹰LOGO】到书签栏,收藏本站!
浏览量:3724 发布时间:2020-08-19 18:38:04
在微信AI背后,技术究竟如何让一切发生?关注微信AI公众号,我们将为你一一道来。今天我们将放送微信AI技术专题系列“微信扫一扫的技术与艺术”的第四篇——《微信扫一扫识物分布式训练》。
导语
微信“扫一扫”识物上线一段时间,由前期主要以商品图(鞋子/箱包/美妆/服装/家电/玩具/图书/食品/珠宝/家具/其他)作为媒介来挖掘微信内容生态中有价值的信息,扩张到各种垂类领域的识别,包括植物/动物/汽车/果蔬/酒标/菜品/地标识别等,识别核心依托于深度学习的卷积神经网络模型。随着每天千万级的增长数据和越来越多的模型参数量,深度学习训练一次时间大概需要一周左右。如何能够快速训练优化模型并上线,成为我们亟待解决的问题。
引言
如今,依托强大的GPU算力,深度学习得到迅猛发展。在图像处理、语音识别领域掀起了前所未有的一场革命。相较于传统的方法,以卷积神经网络(CNN)为代表的深度学习方法可以高度地重点学习数据的特性,在图像处理领域已经取得了统治地位。
随着扫一扫识物日调用量的持续增加,图片数据正以每天千万级的量级增长,在这个争分夺秒的时代里,得数据者得天下。同时,神经网络的复杂性呈爆炸式增长,像15年微软提出图像分类的ResNet模型有7 ExaFLOPs/6千万个参数,17年谷歌的神经网络机器翻译模型有100 ExaFLOPS/87亿个参数。在大部分场景下,模型可以在一台GPU服务器上,使用一个或者多个GPU进行训练。但随着数据集的增大,训练时间也相应增长,有些时候训练需要一周甚至更长时间。因此,如何能够快速迭代优化深度学习模型,成为我们算法开发者亟须解决的问题。
本文主要通过从分布式训练方法的选择、多机通信技术原理进行讲解,基于Horovod的训练框架在微信自研平台Gemini上从无到有打通分布式训练和实验结果来介绍微信扫一扫识物中的深度学习模型分布式训练。
分布式训练
2.1 并行方式
多机多卡相比较于单机多卡,使得模型训练的上限进一步突破。一般我们一台服务器只支持8张GPU卡,而采用分布式的多机多卡训练方式,可以将几十甚至几百台服务器调度起来一起训练一个模型,大大缩短模型训练时间。按照并行方式,分布式训练一般分为数据并行和模型并行两种:
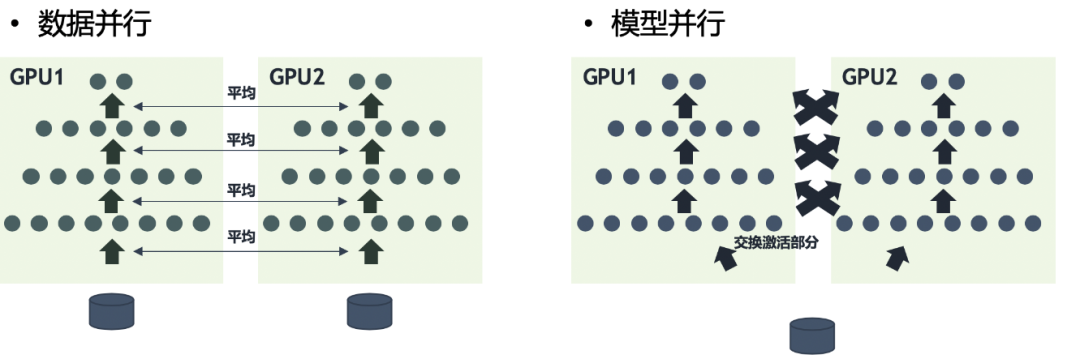
因为模型并行各个部分存在一定的依赖,不能随意增加GPU的数量,规模伸缩性差,在实际训练中用的不多。而数据并行,各部分独立,规模伸缩性好,实际训练中更为常用,提速效果也更好。在实现性、容错性和好的集群利用率上,数据并行优于模型并行。
2.2 系统架构
分布式训练系统架构主要包括两种:一种是Parameter Server Architecture(就是常见的PS架构,参数服务器)和Ring all-reduce Architecture。
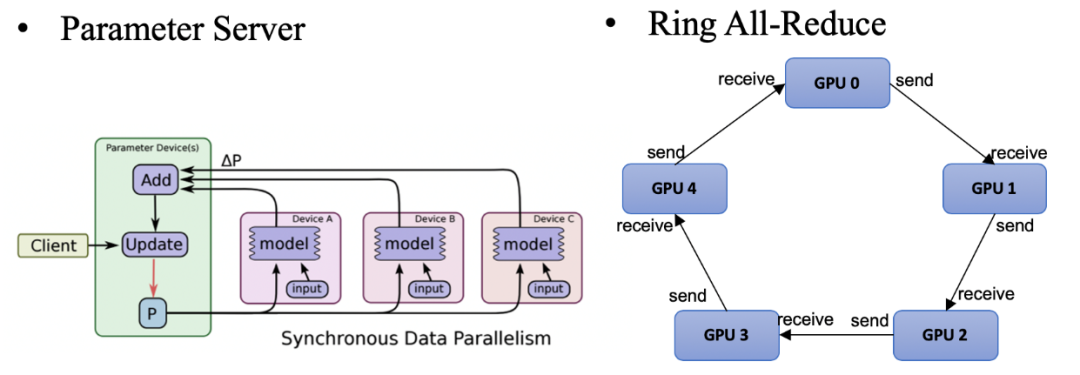
采用PS计算模型的分布式,通常会遇到网络的问题,随着worker数量的增加,其加速比会迅速的恶化。相比PS架构,Ring-allreduce架构网络通信量不随着worker(GPU)的增加而增加,是一个恒定值,集群中每个节点的带宽都被充分利用。
2.3 参数更新
同步更新:所有 GPU 在同一时间点与参数服务器交换、融合梯度。在每轮训练的时候需要汇总所有 worker训练得到的梯度值,然后取平均值来更新参数服务器上的模型参数。
异步更新:所有GPU 各自独立与参数服务器通信,交换、融合梯度。每个 worker 在每轮训练开始前从参数服务器获取模型参数,读取训练数据,进行训练,训练结束后便立即应用梯度来更新参数服务器上的模型参数。
异步更新通信效率高速度快,但往往收敛不佳,因为一些速度慢的节点总会提供过时、错误的梯度方向。同步更新通信效率低,通常训练慢,但训练收敛稳定,因为同步更新基本等同于单卡调大的batch size训练。但是传统的同步更新方法(各个gpu卡算好梯度,求和算平均的方式),在融合梯度时,会产生巨大的通信数据量。
通过比对不同分布式并行方式、系统架构和参数更新,微信扫一扫识物最终选择基于数据并行的参数同步更新的Ring all-reduce的分布式训练方法。
多机通信技术
相比于单机多卡,多机多卡分布式训练要保证多台机器之间是可以互相通信的以及不同机器之间梯度可传递。并行任务的通信一般可以分为点对点通信和集体通信。点对点通信这种模式只有一个sender和一个receiver,实现起来比较简单。而涉及到分布式训练,一般是多台服务器,用到集体通信模式,包含多个sender多个receiver。集体通信常用的通信方式主要有下面几个:broadcast、gather、scatter、reduce、all-reduce等。
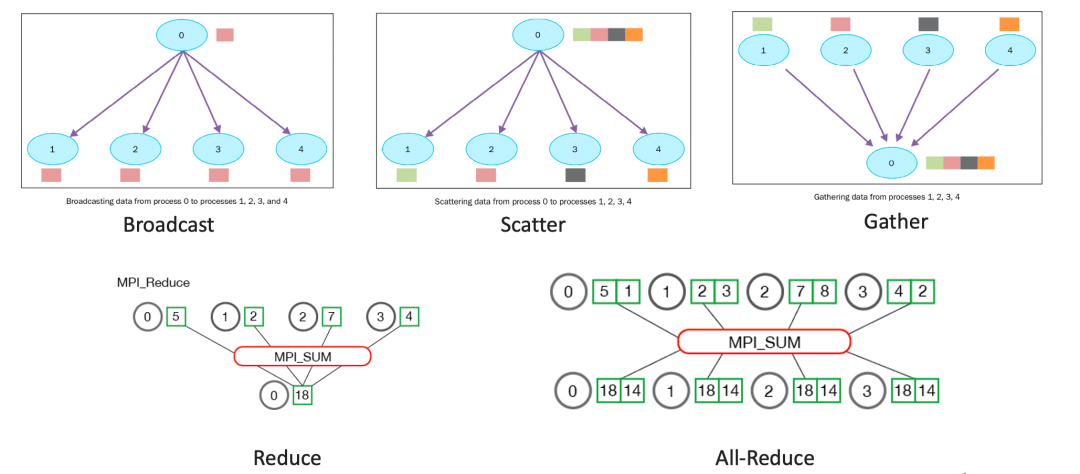
3.1 MPI
在微信的自研gemini训练平台中,多机的通信是基于消息传递接口(Message Passing Interface,MPI)来实现的,MPI是一种基于信息传递的并行编程技术,定义了一组具有可移植性的编程接口,是一种编程接口标准。在基于MPI编程模型中,计算是由一个或多个彼此通过调用库函数进行消息收、发通信的进程所组成。MPI中的通讯器定义了一组能够互相发消息的进程。在这组进程中,每个进程会被分配一个序号,称作秩(rank),进程间显性地通过指定秩来进行通信。MPI涉及到的一些操作包括数据移动,聚集、同步等。
由于深度学习训练参数大多在GPU上的,如果只是依靠MPI来同步参数,参数需要先从GPU搬到CPU,然后不同机器CPU之间再通信,通信结束之后再将参数从CPU搬到GPU,这个过程的通信效率是很低的。所以为了提高通信效率,在训练的过程中使用基于nvidia开发的NCCL进行通信。
3.2 NCCL
NCCL是Nvidia Collective multi-GPU Communication Library的简称,是Nvidia开发的能够实现多GPU的集体通信的库,能够很方便的集成至任何 深度学习的训练框架。在实现 Allreduce、Reduce、Broadcast、Allgather等方面做了很多优化,可以在PCIe、Nvlink、InfiniBand上实现较高的通信速度。目前NCCL1.0版本只支持单机多卡,卡之间通过PCIe、NVlink、GPU Direct P2P来通信。NCCL 2.0会支持多机多卡,多机间通过Sockets (Ethernet)或者InfiniBand with GPU Direct RDMA通信。
Horovod训练框架
目前分布式训练框架有许多,Horovod 是 Uber 开源的一个深度学习工具,囊括了TensorFlow, Keras, PyTorch, and Apache MXNet 这些分布式训练框架。并且Horovod的梯度同步和权值同步利用基于MPI和NCCL的 all-reduce算法,而非参数服务器架构,通信效率更高。Horovod可以利用NVLINK、RDMA、GPUDirectRDMA、自动检测通信拓扑以及回退到 PCIe 和 TCP/IP 通信这些功能。同时,将已有的训练代码改成分布式训练代码,改动量少,简化分布式训练的运行和启动。基于此,微信扫一扫识物选择Horovod的分布式训练框架,在微信的训练平台gemini上进行训练。

Horovod的多机通信初始化是基于MPI的,通过MPI初始化通信环境和进程分配。有几个常用的环境参数:
由于训练采用的是数据并行这种模式,所以需要对数据进行分布式采样。Horovod可以直接调用pytorch自带的分布式采样函数torch.utils.data.distributed.DistributedSampler,

这种方式可以适用于简单的分布式训练任务。但是在识物的检索训练过程中,我们希望dataloader可以做一些平衡采样或者三元组采样,上面的sampler只支持分布式采样。由于pytorch的DataLoader的部分初始化参数之间存在互斥关系,如果自定义了sampler,那么这些参数batch_size,shuffle,batch_sampler,drop_last都必须使用默认值。所以我们重写batch_sampler,将分布式的sampler作为参数传入新构造的batch_sampler,如下所示,
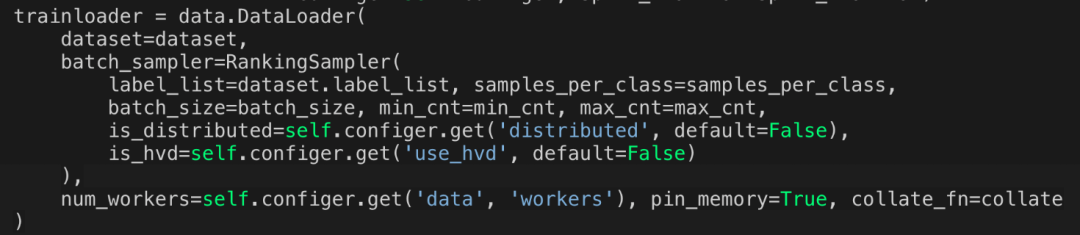
RankingSampler的部分实现。
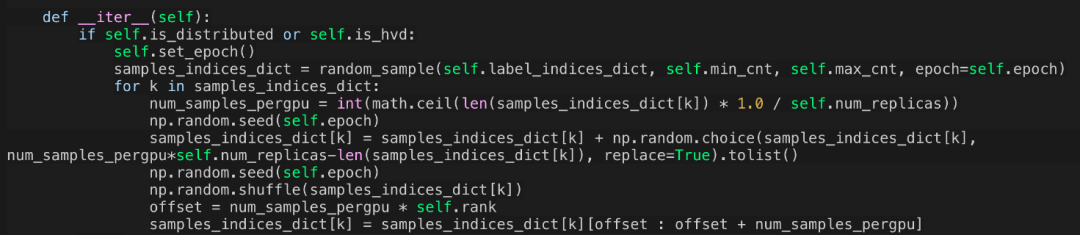
Horovod内部实现了广播操作,使模型在所有工作进程中实现一致性初始化。在加载模型权重的时候,只要在rank0的机器上加载,然后使用广播机制,就可以将参数同步到其他机器上进行权重初始化。

在训练过程中,计算损失函数时需要涉及到allreduce操作,将所有worker的损失规约,然后再进行梯度传播。

最后在保存模型时,只要指定一台机器保存模型即可。

实验结果
分布式训练除了训练阶段的通信要尽可能的快,数据的IO也是需要考虑的地方。扫一扫识物的检索模型是基于大量的图像数据训练的。在进行分布式训练时,每个机器都需要能够读取这些训练数据,起初是把图片文件存到微信自研分布式存储系统wfs上,wfs对yard集群中的每台机器都可见。实验发现,模型在训练过程中,数据加载时间消耗较多,对大量的图片小文件读取很慢。

因为wfs的主要设计目标不是针对分布式训练这种场景的,对大的存储文件更加友好。解决方案有两种,一种是把小的图像文件转成lmdb存储在wfs上,lmdb的优势是基于文件映射IO(memory-mapped),数据速率更好,这种方法不易于我们在代码侧进行各种灵活地操作,每次变更都要重新生成lmdb。另一种方案是将数据挪到机器的挂载的本地盘中,这种方案数据读取很快,但是需要耗费一次数据传输时间。

比较了几种数据传输的方法,一种是将数据切分成多个tar包存放在wfs上,在训练之前从wfs上传到各个机器;另一种是直接将原始图片数据从我们存放的机器上传到各个训练机器。时间耗时如下:
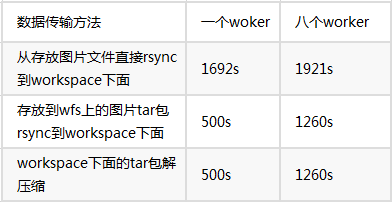
通过对比发现,当申请的worker数较多时,图片文件直接从我们存放的机器传输到训练机器比较快一些,worker数目较少时直接从wfs传输压缩包再解压更快一些。当然随着申请worker的增加,数据传输有个弊端,得每个worker都要传输一遍,这是由于每个worker是独立的环境,每个worker下面的workspace下面是虚拟的挂载盘,互相之间不能访问。
在训练时,分布式训练的加速比和GPU数目正相关。在mnist数据集上基于resnet50测试分布式训练运行时间,
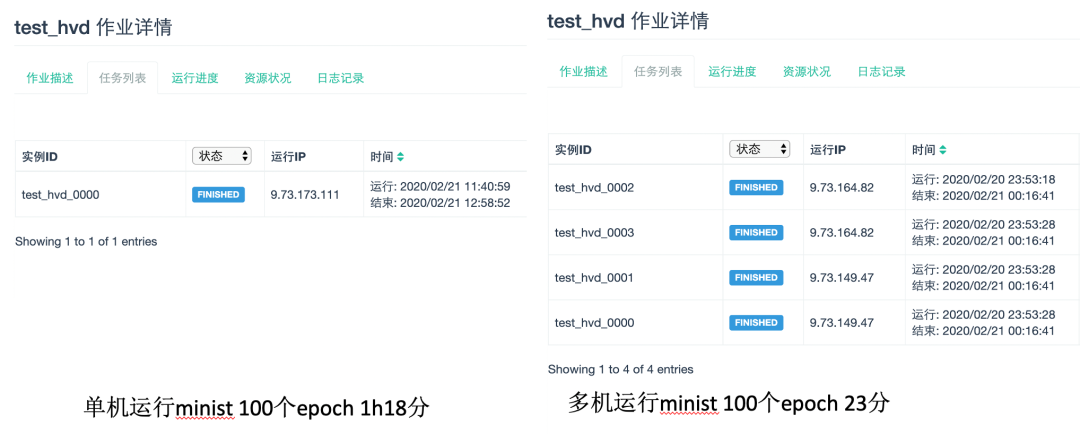
在我们实际项目的模型训练中,基于分布式训练可以将以往需要训练5天甚至一周的时间缩短到1天以内,在同样的时间内,算法开发者可以探索更多的实验,快速反馈更新,大大提高了算法研发的效率。
总结与展望
目前扫一扫识物在微信自研训练平台gemini上能够成功进行分布式训练,但仍然存在以下问题:如何能够高效地存放训练数据,高效地读取数据,比如利用MemCache,将数据读取一次,加载到内存中,通过构造图片list和图片内容的键值对来访问图片内容,这样可以减少共享硬盘的IO的耗时;或者申请的GPU节点可以访问我们数据的存放盘,在数据存放盘搭建个Nginx服务,将数据从硬盘的读取转成网络请求,可以减少数据的传输耗时。道阻且长,行则将至,在我们后续工作中将针对这些问题进行探索。
注:此文章来源于微信AI;

微信在线客服
请提供详细的截图大图+文字说明您的问题



微信扫码查看帮助
扫码关注,获取各种排版小技巧,黑科技!复制成功
Copyright © xmyeditor.com 2015-2025 河南九鲸网络科技有限公司
ICP备案号:豫ICP备16024496号-1 豫公网安备:41100202000215 经营许可证编号:豫B2-20200040


